
How to Run an LLM as Powerful as DeepSeek R1 Locally with LM Studio With Just 24 GB VRAM
How Powerful Can A Local LLM Actually Be, With Just 24 GB VRAM?


"AI Disruption" Publication 5000 Subscriptions 20% Discount Offer Link.

Hi everyone.
First, let me say that I am thrilled to write a guest post for this publication.
Meng Li is someone I look up to for his consistency and depth, and I am delighted to feature a post on AI Disruption, his signature blog. Sincere thanks to @Meng Li for this opportunity.

Simply The Best Local LLM Tool
LM Studio is the best tool available now to run LLMs locally, without telemetry.
It is free for personal users.
You can download it from lmstudio.ai.
It is available for all versions of Windows, Linux, and Mac.
While it is not open source, it has many features that set it apart from other tools like Ollama and GPT4All.
You have several advantages when you use LM Studio.
A quick summary:
User-Friendly Interface:
The ease-of-use of the GUI offered by LM Studio is unparalleled by any other Local LLM tool.
Local Inference:
Everything is run locally and no data is sent to any server in the cloud, i.e. no telemetry is collected.
Hugging Face Integration:
Allows you completely free access to almost 1.5 million models on the HuggingFace Models Collection
Model Exploration and Selection:
Provides advanced model browsing capabilities, including sorting and filtering by popularity and download count.
Performance Optimization:
LM Studio also shows you which models are compatible and uses GPUs automatically with no configuration required.
Quantization Support:
Nearly all models offer support for quantization using the famous GGUF format.
Customization Options:
Allows users to adjust advanced parameters such as temperature, context length, and repeat penalty for fine-tuned responses.
Local Server Deployment:
If you are an AI Engineer, you can set up a local Inference Server and use multiple models at the same time.
Command-Line Interface (CLI):
Offers a CLI for managing models and servers directly from the terminal with the lms CLI tool.
RAG Support:
Provides good support for RAG and customizing local LLM operation through JSON configuration files within the GUI.
Agentic AI:
AI Agent developers will find LM Studio optimally suited to testing multiple agents at the same time locally before deployment to the cloud.
Image Models:
When image models are downloaded, the LM Studio app provides built-in image support for the model chosen.
Serving Over Network:
The latest version lets you expose your LLM endpoint ‘OpenAI-style’ over the Internet and also supports REST clients.
Completely Free:
For individuals, even advanced AI Engineering support is free. Only businesses require a license. As a follow-up:
No API Costs:
For individuals, no money required to create advanced AI apps for heavy-duty APIs for OpenAI or other providers. Everything is free!
The User Interface

Source: LM Studio Website Blog
The Democratization of AI Engineering
Now everyone knows that AI agents are the future, and everyone wants a slice of the pie.
RAG (Retrieval-Augmented Generation) is also an ultra-hot topic.
Graph-based RAG (knowledge graphs) is also a very active topic today.
Generative AI can also involve other tasks like finetuning and customizing existing models.
JSON formats should be a familiar topic, and one must also know key terms like:
Temperature: The amount of randomness in the model
System_Prompt: The expertise base of the LLM
Model_Name: The name of the model currently being used
Context_Window: The maximum number of tokens used by the LLM
Output_Format: The structure of the output generated by the LLM
All these and much more can easily be changed with the LM Studio GUI.
But we are getting ahead of ourselves.
The first thing to note is the 1.49M plus models available to us on the HuggingFace website.
Every model is quantized (almost) to fit into even 8 GB RAM systems.
While 32 GB+ RAM and 12 GB+ VRAM is required for most models:
The wonderful thing about quantized models is that it allow huge models to run even on systems like mine:
With 16 GB RAM and a tiny 2 GB VRAM configuration.
If you are an AI Engineer or aspiring to be one, do not settle for less than 32 GB RAM and 24 GB VRAM.
That deep investment will reap rich dividends in the quality of your Generative AI apps and Multi-Agent apps.
Also, LM Studio allows you to run multiple local LLMs and access the Internet with Multiple Agents.
Even 64 GB RAM would be worth the investment in this case, and a 32 GB VRAM would be ideal for your setup.
A Little Background on HuggingFace Models

The AI Agents of the future will be extremely powerful!
While there are almost 1.5M models available on HuggingFace:
You have to choose models with great care according to your needs.
While every system with 1 GB of RAM can support 1 billion parameter models:
Quantized models can be run on even fewer memory requirements per 1B parameters.
But first, what is quantization?
According to our source:
“Quantization for large language models (LLMs) is a model compression technique that reduces the precision of model weights and activations from high-precision data types (e.g., 32-bit floating-point numbers) to lower-precision types (e.g., 8-bit or 4-bit integers). This process decreases the model's size, memory usage, and computational requirements, making it more efficient for deployment on devices with limited resources, such as edge devices or smartphones.”
And low-end laptops as well.
LLMs are typically stored with billions of 32-bit floating point parameters - billions of them.
For example, GPT 3.5 had a whopping 175 billion parameters.
Codestral-22B, the latest coding LLM from Mistral AI, has (you guessed it) 22 billion parameters.
However, when quantized, a 22 GB model can be shrunk to even 8.27 GB, allowing me to run it with LM Studio even on my 16 GB RAM system.
The beauty of this technique is that in many cases, performance is not affected significantly.
However, that also depends on whether the technique is performed correctly.
There are several methods and caveats to quantization, but they go beyond the scope of this article right now.

Screenshot of LM Studio 0.3.12 running on my system (I love dark mode)
LLMs can be run locally with quantization, but currently, there is another revolution that is changing the generative AI landscape.
Small Language Models
In recent years, we have seen the emergence of Small Language Models (SLMs for short).
Many SLMs have been created that rival LLMs in their performance on certain tasks.
Some of the best small language models (less than 16B parameters) include:
Llama 3.1 8B - Meta AI
Llama 3.1 is an open-source model that offers a balance between size and performance.
Ideal for applications requiring a mix of performance and resource efficiency.
Gemma2 - Google DeepMind
Gemma2 is a smaller variant of DeepMind's models, designed for resource-constrained environments.
Suitable for on-device AI applications where low latency and efficiency are crucial.
Qwen 2 - Alibaba
Qwen 2 is a compact model known for its versatility and ease of integration into various applications.
Ideal for mobile or edge AI applications where space and resources are limited.
Phi-4 - Microsoft
Phi-4 is a 14 billion parameter model that excels in complex reasoning tasks, particularly in math and STEM-focused areas.
Best suited for applications requiring strong reasoning capabilities, especially in educational or technical contexts.
Mistral Nemo - Mistral AI
Mistral Nemo is a small language model designed for specific tasks like conversational AI.
Suitable for chatbots or voice assistants that require efficient and responsive interactions.
You can run all of the models above, multiple models, at the same time, with LM Studio.
I strongly encourage you to try out Phi-4, because it outperforms even several LLMs on multiple benchmarks.
Running several LLMs simultaneously, you can create powerful Multi-Agent systems.
And you can test your AI agents extensively in production environments without spending a penny on API costs.
With LM Studio, the sky is not the limit, we have an endless exploration into space without limits.
Except perhaps, your machine specifications!
Now you may fully understand why high-end machines are such a big advantage for AI Engineers.
But I can develop AI agents as well on my system, and I have just 2 GB VRAM.
LM Studio and HuggingFace model quantization democratize Generative AI development.
Now, as promised: an LLM as powerful as DeepSeek R1 on your local computer!
A Step-By-Step Method to Run the QwQ 32B LLM on Your Local System Using LM Studio

QwQ is as Powerful as DeepSeek R1 on Several Benchmarks - hence the inspiration for the title of this article.
Step 1: Download the 4-bit Quantized QwQ-32B Model
Open LM Studio and navigate to the "My Models" section.
Search for "QwQ-32B" and look for a 4-bit quantized version.
Download the AWQ 4-bit quantized model
Step 2: Load the Model in LM Studio
In LM Studio, navigate to the "My Models" section.
Click on "Add Model" and select the downloaded 4-bit quantized QwQ-32B model file.
Step 3: Run the Model
Go to the "Chat" section in LM Studio.
Select the loaded 4-bit quantized QwQ-32B model from the dropdown menu.
Step 4: Interact with the Model
Start asking questions or providing prompts in the chat window.
The model will process your input and generate responses.
Hardware Requirements
A GPU with at least 24 GB of VRAM is recommended for running the 4-bit quantized model efficiently.
Models like the NVIDIA RTX 4090 are suitable.
At least 32 GB of RAM is recommended, but more is better for smoother performance.
Notes
4-bit quantization significantly reduces VRAM usage compared to full-precision models, making it more feasible to run on consumer-grade GPUs.
While quantization reduces VRAM requirements, it may slightly affect model accuracy compared to full-precision versions.
In case you are not aware of the latest benchmarks, QwQ beats DeepSeek R1 on many of the latest benchmarks for LLMs.
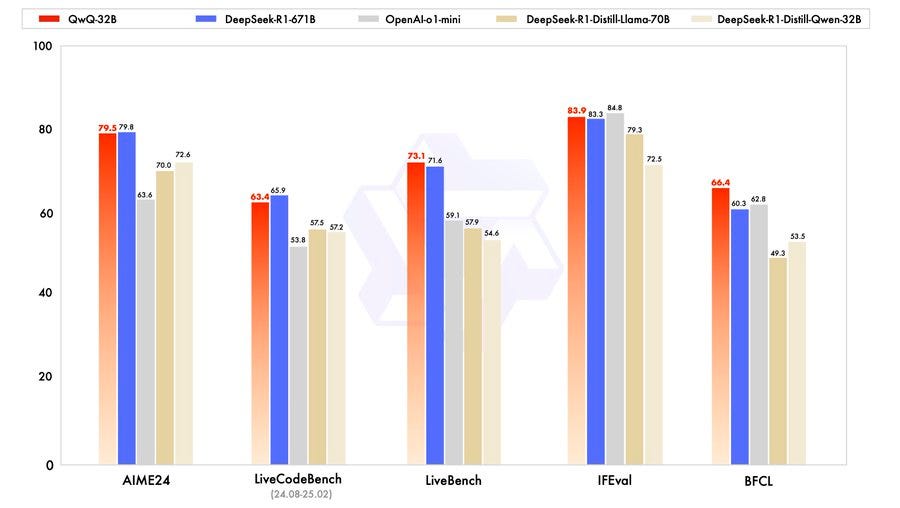
Think about that for a minute.
You are running a model on par with the most powerful LLMs in the world, like DeepSeek R1:
For free - no cost at all
No Nvidia A100 or H100 expensive GPUs
No API Costs
No latency - it's running 100% locally
And safeguarding your private information
This almost feels like cheating!
You are essentially running one of the most powerful LLMs in the world locally, free!
If I were an AI Engineer, I would download LM Studio ASAP!
And I would be looking at that Multi-Agent feature and the Local Inference Server running over the Internet.
Conclusion - The Beginning Of Your AI Engineer Career
Bill Gates was famously asked about his picks for the careers that would survive the AI revolution.
He picked three jobs, but I believe the first job was the most important - an AI Engineer.
With LLMs everywhere, and AI Agents automating most tasks:
An AI Engineer seems to be the most likely career to survive the AI revolution.
If you are a young student reading this, you now know where to go.
If you are a fresher beginning a career, upskill soon.
If you are a seasoned professional in IT, embrace AI and try to apply it to your domain.
And remember:
Never lose your enthusiasm.
Never lose the love for the job.
You are in a privileged position just reading this article.
Because you have the chance to work in one of the most highly sought-after jobs in the world.
By the grace of God, may that enthusiasm never leave you.
Enjoy AI engineering.
And focus on it - with a laser-sharp view.
All the very best in your upcoming career!

May you stand tall in the upcoming AI revolution in the near future!
References
All Images other than LM Studio screenshots generated by NightCafe Studio, are available at this link:
https://creator.nightcafe.studio/ (Free AI Art Generator: All the best AI models in one place)
 | A guest post by
|
I installed it. It is very easy. But it is slow, probably because my laptop isn't very big. Your article helped me very much. Thanks
Thanks. I am looking into running a LMM localy. This will certainly help.
I am no developper, just an end-user wanting to have control over my own privacy.