
RAG-Finetuned Llama 3 Surpasses GPT-4! NVIDIA GaTech Chinese Scholars Propose RankRAG Framework
Discover how RankRAG, a new fine-tuning framework, enhances Llama 3 to outperform GPT-4 in text generation tasks requiring extensive factual knowledge.

In text generation tasks requiring extensive factual knowledge, RAG has become a common LLM deployment technique.
However, a recent paper by Georgia Tech and NVIDIA suggests that RAG can be more than just a part of the inference pipeline. The concept can be integrated into the fine-tuning stage, leading to the RankRAG framework.
Their approach involves expanding the model's capabilities through fine-tuning, allowing the LLM to handle retrieval and ranking tasks typically managed by separate models. This results in improved data efficiency and significantly enhanced model performance, surpassing the ChatQA-1.5 series introduced in May.
On nine general benchmarks and five biomedical knowledge-intensive benchmarks, RankRAG, fine-tuned with Llama 3 8B/70B, outperformed the ChatQA-1.5 models, Llama3-ChatQA-1.5-8B, and Llama3-ChatQA-1.5-70B.

https://chatqa-project.github.io/
RAG (Retrieval-Augmented Generation) is widely used for customizing LLMs, especially for knowledge-intensive NLP tasks. It helps models access "long-tail knowledge" and the latest information without altering weights, and adapting to specific domains.
Typically, RAG works by having a dense text encoder model retrieve top-k text segments from an external database for a given query. These segments are then input to the LLM for generation.
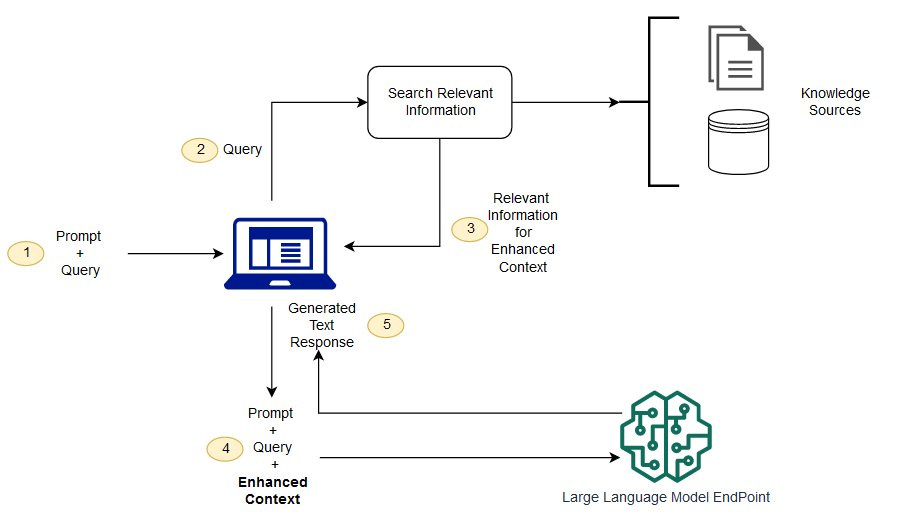
While this pipeline is intuitive and widely used, the authors point out inherent limitations, starting with the choice of k value.
A large k (e.g., top-100) can overwhelm even LLMs with long-context windows. The performance quickly plateaus as k increases. Previous research also shows that a k value around 5 or 10 yields more accurate results, as too much context can introduce irrelevant information.

