


Open-Sourcing Everything: NVIDIA's Llama-Nemotron Outperforms DeepSeek-R1
NVIDIA's Llama-Nemotron: Open, Efficient AI Models Outperform DeepSeek-R1 in Reasoning. Free for Commercial Use!

"AI Disruption" Publication 6300 Subscriptions 20% Discount Offer Link.

In today's rapidly evolving landscape of large-scale models, reasoning capability stands as a critical metric for assessing model intelligence and has become a focal point of competition among AI enterprises.
However, in recent years, reasoning efficiency has emerged as a key limiting factor in model deployment and performance.
To address this, NVIDIA introduced the Llama-Nemotron series (built on Meta AI’s Llama models)—an open family of large-scale models designed for efficient reasoning. These models boast exceptional reasoning capabilities, high reasoning efficiency, and enterprise-friendly open licensing.
The series includes three model sizes: Nano (8B), Super (49B), and Ultra (253B), along with an independent variant, UltraLong (8B, supporting ultra-long contexts).
These models are far from ordinary. They not only deliver outstanding reasoning capabilities but also provide open licensing for enterprise use.
Model weights and partial training data are publicly available on Hugging Face, governed by the NVIDIA Open Model License and Llama community license, enabling commercial use.
The Llama-Nemotron series is among the first open-source models to support dynamic reasoning mode switching, allowing users to seamlessly toggle between standard chat mode and reasoning mode during inference, greatly enhancing interaction flexibility.
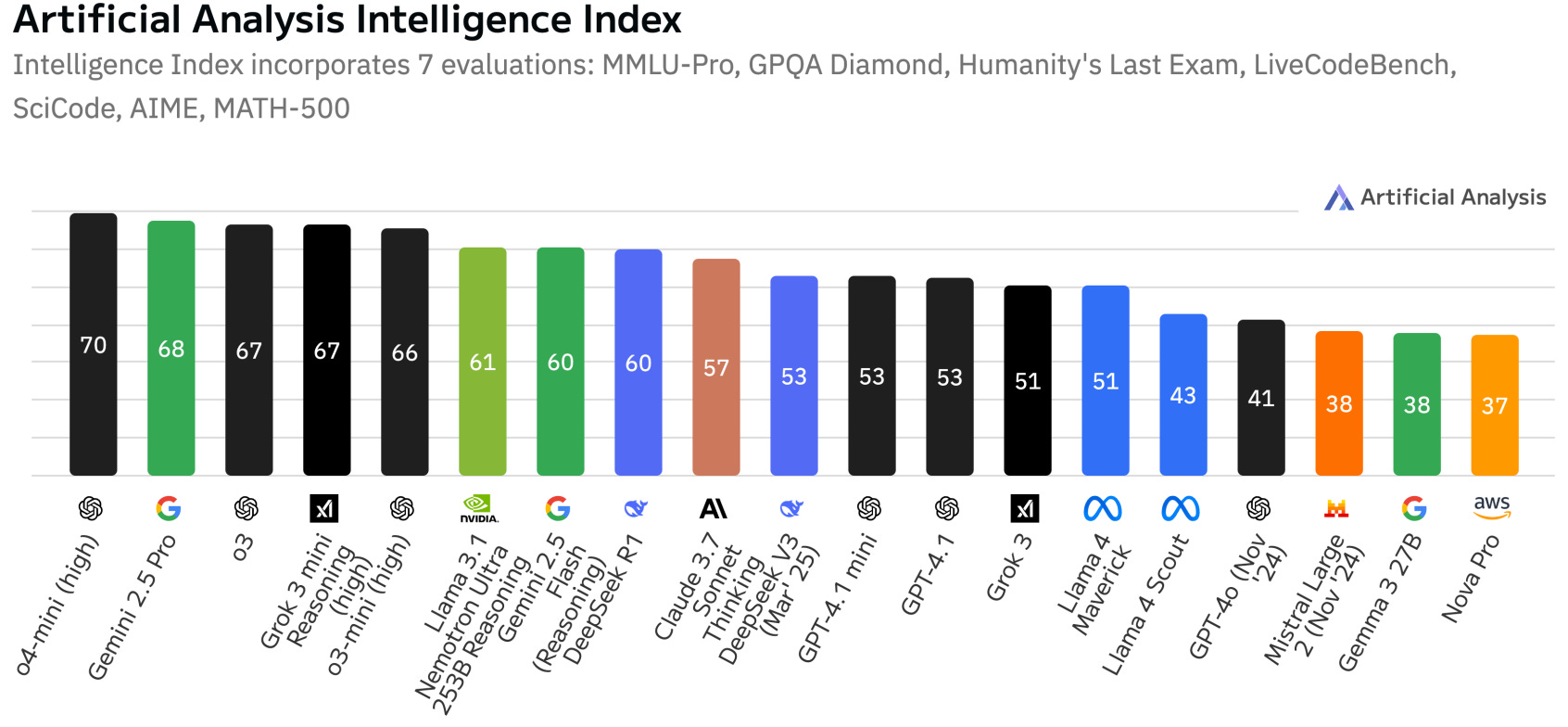
Evaluations were conducted using reasoning and non-reasoning benchmarks, revealing that the Llama-Nemotron series performs impressively across different scales. Notably, the LN-Ultra model significantly outperforms DeepSeek-R1 in terms of reasoning throughput and deployment efficiency.
Llama-Nemotron models undergo a multi-stage post-training process to enhance performance in both reasoning and non-reasoning tasks. The supervised fine-tuning phase focuses on tasks such as mathematics, coding, reasoning, and tool invocation. The reinforcement learning phase employs the REINFORCE algorithm (RLOO) and Reward-aware Preference Optimization (RPO) to optimize skills like dialogue generation and instruction following.
Qwen and DeepSeek-R1 play critical roles in Llama-Nemotron’s training. Qwen (e.g., Qwen2.5-32B-Instruct) handles the generation, classification, and decontamination of math and science data to create high-quality training sets. DeepSeek-R1, as the core teacher model, generates multi-step reasoning and code solutions, transferring deep logical capabilities to the target model through supervised fine-tuning and reinforcement learning.
Curious about how NVIDIA built the Llama-Nemotron series? What unique training methods lie behind it?
Let’s dive deeper into the secrets behind its creation.