
DeepSeek Releases R1-Lite-Preview: Free 50 Daily Uses, Outshines OpenAI in Math and Coding
Explore DeepSeek-R1-Lite-Preview: a groundbreaking reasoning model surpassing OpenAI in math & coding benchmarks. Free 50 daily uses with transparent thought chains!

DeepSeek Strikes Again with a Game-Changing Announcement
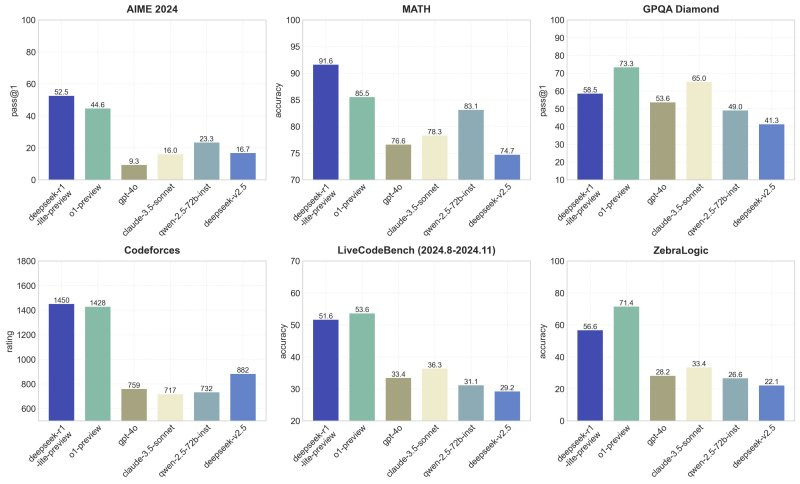
Last night, DeepSeek unveiled its new reasoning model, DeepSeek-R1-Lite-Preview, which aims to challenge the dominance of OpenAI's o1 model, the reigning champion for over two months.
In prestigious benchmarks like the American Invitational Mathematics Examination (AIME) and top global programming competitions like Codeforces, DeepSeek-R1-Lite-Preview has already significantly outperformed leading models such as GPT-4o, even surpassing OpenAI o1-preview in three key areas.

The secret behind this success? "Deep Thinking."
By leveraging more reinforcement learning, a native chain-of-thought mechanism, and extended reasoning times, the model delivers stronger performance—an approach increasingly recognized as essential in the AI field. This methodology closely mirrors how humans engage in deep, deliberate thinking.
Unlike OpenAI's o1, DeepSeek-R1-Lite-Preview takes things a step further by displaying a "thought chain" during its reasoning process. This chain outlines various reasoning paths and explains the model’s decisions step by step, making its internal processes more transparent.
It's akin to someone meticulously writing out every step of a solution while solving a problem—but DeepSeek-R1-Lite-Preview goes even further by documenting its inner monologue as well.
According to DeepSeek, the R1 series models utilize reinforcement learning and extensive reflection and validation during their reasoning processes. These thought chains can span tens of thousands of words in length.
