
Alibaba Releases 3 Models, Setting 32 New SOTA Records
Alibaba's Qwen3-Omni beats Gemini-2.5-Pro & GPT-4o, achieving 22 SOTA results. A leading multimodal AI model

"AI Disruption" Publication 7800 Subscriptions 20% Discount Offer Link.
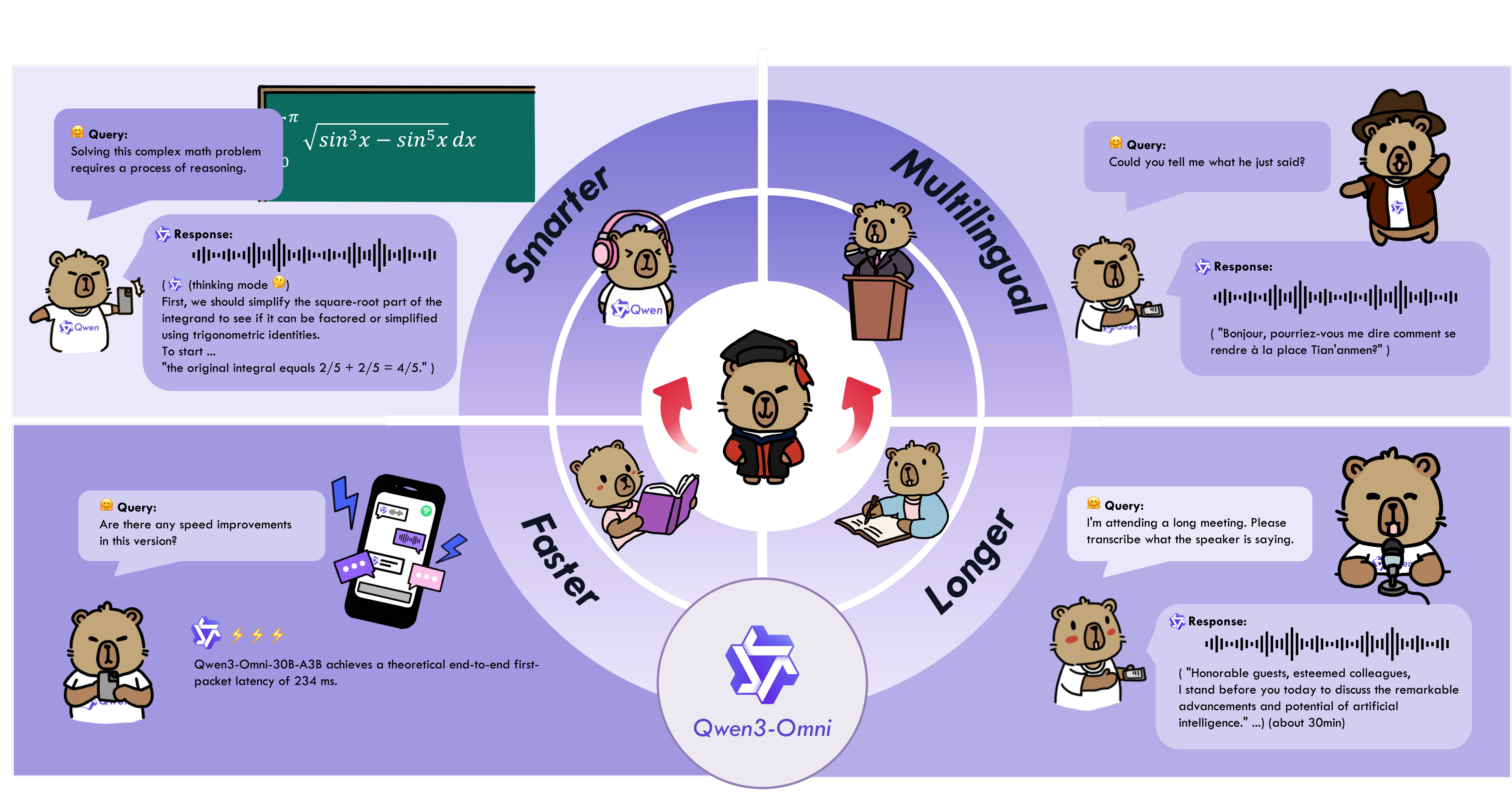
Alibaba Continues to Advance Multimodal Large Models
Alibaba's Tongyi large model team has launched three major innovations: the open-source native fully multimodal large model Qwen3-Omni, the speech generation model Qwen3-TTS, and the updated image editing model Qwen-Image-Edit-2509.
Qwen3-Omni can seamlessly process multiple input formats, including text, images, audio, and video, and simultaneously generate text and natural speech output through real-time streaming responses.
It achieved 32 open-source SOTA results and 22 overall SOTA results across 36 audio and audiovisual benchmark tests, surpassing closed-source strong models such as Gemini-2.5-Pro, Seed-ASR, and GPT-4o-Transcribe, while also reaching SOTA-level performance in image and text tasks among models of similar size.
Qwen3-TTS supports 17 voice tones and 10 languages, outperforming mainstream products like SeedTTS and GPT-4o-Audio-Preview in speech stability and voice similarity evaluation.
The primary update of Qwen-Image-Edit-2509 is support for multi-image editing, enabling the combination of different elements from various images, such as person+person, person+object, etc.
