Alibaba Open-Sources First CoT Audio Model, Mastering Audio-Visual Sync
Alibaba's ThinkSound: First CoT audio model for video dubbing. Generates frame-perfect sound effects using Chain of Thought reasoning. Open-source on GitHub.

"AI Disruption" Publication 7000 Subscriptions 20% Discount Offer Link.

Has AI audio evolved to this level??
Turn on the sound 🦻 and quickly experience the latest feel:
Simulating baby crying sounds with such ups and downs, soul-stirring rhythm that perfectly syncs with the baby's facial expressions and postures.
A train approaching from far to near, with the entire background audio having rich spatial layering that feels completely natural.
Even trumpet performances can match the sound perfectly with the performer's movements.
That's right, this is ThinkSound, the latest open-source universal audio generation model released by Alibaba's Tongyi Speech team, primarily used for video dubbing, focusing on creating dedicated matching sound effects for every frame.
According to the introduction, it's the first to introduce this year's popular CoT (Chain of Thought) reasoning into the audio field, solving the problem where traditional video soundtrack technology can only generate monotonous background music and struggles to capture dynamic details and spatial relationships in the visuals.
This means AI can now think step-by-step like professional sound designers, generating high-fidelity audio that syncs with visuals by capturing visual details.
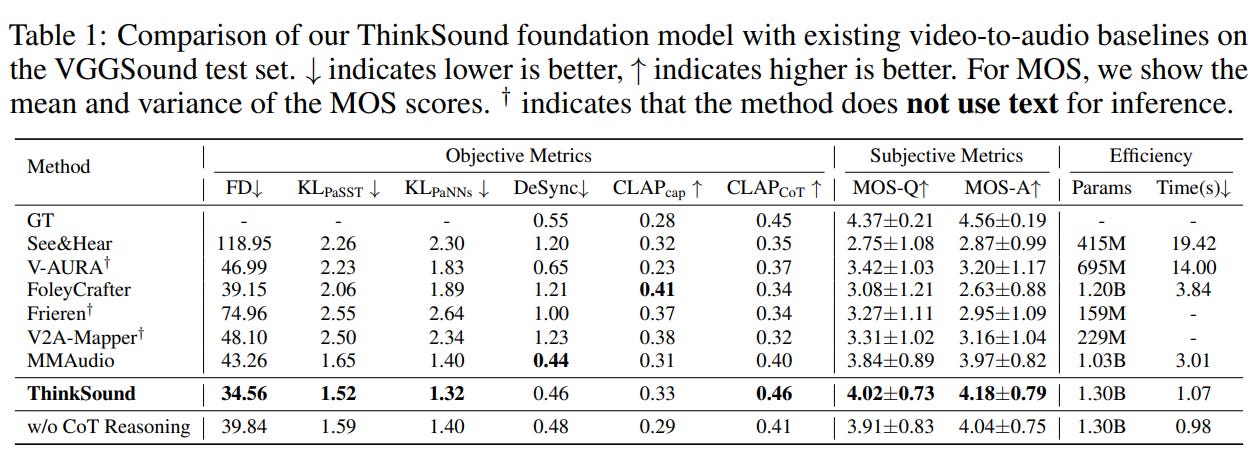
Official evaluations show that ThinkSound achieved significant improvements across core metrics on the industry-renowned audio-visual dataset VGGSound, compared to 6 mainstream methods (Seeing&Hearing, V-AURA, FoleyCrafter, Frieren, V2A-Mapper, and MMAudio).