
Active Learning: A Smarter Way to Start Machine Learning Projects
Optimizing data labeling for efficient and effective model training


"AI Disruption" publication New Year 30% discount link.
About the Author: Daniel García is a Machine Learning engineer who shares his adventures (and mishaps) in the world of AI. Through 'The Learning Curve,' he explores ideas, tools, and lessons learned, blending insight with humor to make complex topics accessible and enjoyable.

Below is a guest article by Daniel.
When embarking on a new machine learning (ML) project, the initial stages often determine the trajectory of success or failure. Traditionally, practitioners follow a standard approach: collect a large dataset, label it, train a model, and iterate until the desired performance is achieved. While this method has proven effective, it can be resource-intensive and inefficient, especially for projects with limited budgets or scarce data. Enter active learning, a technique that flips the script by making data labeling more strategic and efficient.
What Is Active Learning?
Active learning is a subset of machine learning where the algorithm actively selects the most informative data points to label, rather than passively relying on a randomly labeled dataset. The core idea is to optimize the data-labeling process by focusing efforts on examples that will maximize the model's performance.
In an active learning pipeline:
An initial model is trained on a small labeled dataset.
The model identifies areas of uncertainty or disagreement (e.g., ambiguous or poorly predicted samples).
These samples are sent for labeling by a human expert.
The newly labeled data is added to the training set, and the model is retrained.
The process repeats until the model reaches acceptable performance or labeling constraints are met.
The following image illustrates a typical active learning workflow:

In this diagram:
Data Extraction: Data is collected from various sources, such as YouTube, Google, or Wikipedia, to serve as the initial dataset.
Labels Generation: The model generates preliminary labels for the extracted data based on its current training.
Labels Checking: These labels are validated, corrected, or improved by human experts to ensure accuracy.
Manual Labeling: If no model is available or the model fails to generate useful labels, human annotators manually label the data points.
Database (DB): Validated and labeled data is stored in a database for further processing.
Model Training: The labeled data from the database is used to iteratively train and refine the deep learning (DL) model.
This iterative process ensures that the model improves efficiently by focusing on the most informative and challenging data points.
Differences Between Active Learning and the Standard Approach
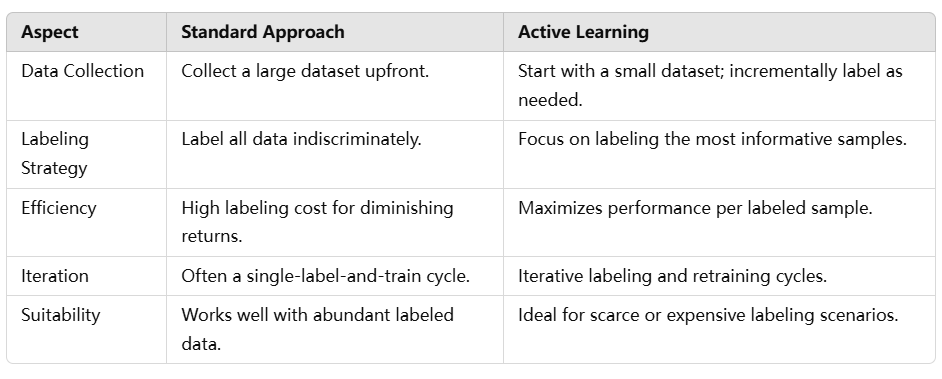
Why Use Active Learning?
Cost Efficiency: Labeling data can be expensive, especially when domain expertise is required. Active learning minimizes this cost by reducing the number of labeled samples needed for high performance.
Faster Model Improvement: By focusing on difficult or uncertain samples, active learning accelerates the model's learning process, allowing for quicker improvements compared to randomly labeled data.
Handling Data Scarcity: In many real-world scenarios, collecting and labeling large datasets is impractical. Active learning shines in these situations by maximizing the utility of available data.
Reducing Labeling Fatigue: Annotators often face fatigue when labeling redundant or obvious samples. Active learning ensures that their efforts are directed toward challenging and meaningful examples.
When to Use Active Learning
Active learning is particularly beneficial in scenarios such as:
Niche Applications: Where data collection and labeling require specialized expertise (e.g., medical imaging, legal documents).
Imbalanced Data: Where certain classes are underrepresented, and targeted labeling can help balance the dataset.
Uncertainty in Labels: Where even experts might disagree, and the algorithm’s insights can guide consensus-building.
Practical Implementation
To implement active learning in your project:
Choose an Uncertainty Metric: Common metrics include entropy, margin sampling, and least confidence. These help identify the samples where the model is most unsure.
Select a Query Strategy: Decide how many samples to label per iteration. Balancing between exploration (diverse samples) and exploitation (high-uncertainty samples) is key.
Iterate Systematically: Regularly retrain the model and reassess the data pool to adapt to the model’s evolving weaknesses.
Use a Feedback Loop: Ensure human experts are integrated seamlessly into the labeling and validation steps to maintain high-quality data.
Key Takeaways
Active learning is not a one-size-fits-all solution, but it’s an invaluable approach when facing limited resources, expensive labeling, or sparse datasets. By enabling smarter labeling decisions and focusing on the most informative data, active learning allows machine learning projects to achieve better performance faster and with fewer resources.
For practitioners starting from scratch, adopting active learning could mean the difference between building a robust model efficiently and drowning in a sea of unnecessary data.
New Year Publication Offer

The "AI Disruption" publication has gained 4,000 followers. It was created over nine months ago. So far, 600 articles have been completed, and six columns have been written:
 | A guest post by
|